![<?echo $_SERVER['SERVER_NAME'];?>](/template/twentyseventeen/skin/images/header.jpg)
Artificial intelligence is hot.
Technological innovation is the fundamental driving force of economic growth. Among these technologies, the most important are what economists refer to as "universal technologies", such as steam engines, internal combustion engines, and electricity. In today’s era, artificial intelligence is the most important “general-purpose technologyâ€. In particular, the combination of industry and artificial intelligence unleashes the potential of the industry and reshapes our lives.
The driving force behind the attention and revolutionary progress of artificial intelligence is actually "machine learning".
Machine learning is actually a multi-domain interdisciplinary subject, which involves computer science, probability and statistics, function approximation theory, optimization theory, cybernetics, decision theory, algorithm complexity theory, experimental science and other disciplines. Therefore, the specific definition of machine learning has many different sayings, which are cut from the perspective of a related discipline. But generally speaking, the core issue of its concern is how to use computational methods to simulate human-like learning behavior: to obtain patterns (or models) from historical experience and apply them to new similar scenarios.
So what exactly are we talking about when we talk about machine learning? What cutting-edge technologies do practitioners need to master? In the future, what technological trends are worth looking forward to?
Look at the cutting edge: machine learning techniques you need to master
In recent years, many new machine learning technologies have received extensive attention, and they have also provided effective solutions to solve practical problems. Here, we briefly introduce deep learning, reinforcement learning, adversarial learning, dual learning, transfer learning, distributed learning, and meta-learning.
â–ŒDeep Learning
Unlike traditional machine learning methods, deep learning is a class of end-to-end learning methods. Based on multi-layer nonlinear neural networks, deep learning can learn directly from raw data, automatically extract features and abstract them layer by layer, and finally achieve regression, classification or sorting purposes. Driven by deep learning, people have successively made breakthroughs in computer vision, speech processing, and natural language, reaching or even surpassing human level. The success of deep learning is mainly attributed to three factors—big data, big models, and big computing, so these three directions are the hotspots of current research.
In the past few decades, many different deep neural network structures have been proposed, such as convolutional neural networks, which are widely used in computer vision, such as image classification, object recognition, image segmentation, video analysis, etc.; recurrent neural networks , which can process variable-length sequence data, and is widely used in natural language understanding, speech processing, etc. The encoder-decoder model (Encoder-Decoder) is a common framework in deep learning, which is mostly used for image or sequence generation, such as relatively hot machine translation, text summarization, and image captioning problems.
▌ Reinforcement learning
In March 2016, AlphaGo, designed by DeepMind based on deep convolutional neural network and reinforcement learning, defeated top professional chess player Lee Sedol by 4:1, becoming the first computer program to defeat a professional Go player without handicap. This competition has become a milestone event in the history of AI, and it has also made reinforcement learning a hot research direction in the field of machine learning.
Reinforcement learning is a subfield of machine learning that studies how an agent learns in a dynamic system or environment in a "trial and error" manner, and the rewards obtained by interacting with the system or environment guide behavior, thereby maximizing cumulative reward or long-term return. Due to its generality, the problem is also studied in many other disciplines, such as game theory, control theory, operations research, information theory, multi-agent systems, swarm intelligence, statistics, and genetic algorithms.
â–ŒTransfer learning
The purpose of transfer learning is to transfer models trained for other tasks (called source tasks) to new learning tasks (called target tasks) to help the new tasks solve technical challenges such as insufficient training samples. This is possible because there are correlations between many learning tasks (such as image recognition tasks), so the knowledge (model parameters) summarized from one task can be helpful for solving another task. Transfer learning is currently one of the research hotspots in machine learning, and there is still a lot of room for development.
▌ Adversarial Learning
There is a potential problem with traditional deep generative models: due to maximizing probability likelihood, the model is more inclined to generate extreme data, which affects the effect of generation. Adversarial learning uses adversarial behaviors (such as generating adversarial samples or adversarial models) to strengthen the stability of the model and improve the effect of data generation. In recent years, the Generative Adversarial Network (GAN), which uses the idea of ​​adversarial learning for unsupervised learning, has been successfully applied to the fields of image, speech, text, etc., and has become one of the important technologies of unsupervised learning.
â–ŒDual learning
Dual learning is a new learning paradigm. Its basic idea is to use the dual properties between machine learning tasks to obtain more effective feedback/regularization to guide and strengthen the learning process, thereby reducing the dependence of deep learning on large-scale manual annotation data. . The idea of ​​dual learning has been applied to many machine learning problems, including machine translation, image style transfer, question answering and generation, image classification and generation, text classification and generation, image-to-text and text-to-image, etc.
â–ŒDistributed Learning
Distributed technology is an accelerator of machine learning technology, which can significantly improve the training efficiency of machine learning and further expand its application scope. When "distributed" meets "machine learning", it should not be limited to the multi-machine parallelization of serial algorithms and the technology of underlying implementation. We should, based on a complete understanding of machine learning, integrate distributed and machine learning more tightly bound together.
â–ŒMeta learning
Meta learning is a new research hotspot in the field of machine learning in recent years. Literally understood, meta-learning is learning how to learn, focusing on the understanding and adaptation of learning itself, rather than just completing a specific learning task. That is, a meta-learner needs to be able to evaluate its own learning method and adjust its own learning method according to a specific learning task.
Watching Trends: Grasping the Future of Machine Learning
Although machine learning has made great progress and solved many practical problems, objectively speaking, there are still huge challenges in the field of machine learning.
First of all, the mainstream machine learning technology is a black box technology, which makes us unable to predict the hidden crisis. To solve this problem, we need to make machine learning interpretable and intervenable. Secondly, the computational cost of current mainstream machine learning is very high, and it is urgent to invent lightweight machine learning algorithms. In addition, in physics, chemistry, biology, and social sciences, people often use some simple and beautiful equations (such as second-order partial differential equations like the Schrödinger equation) to describe the profound laws behind appearances. So in the field of machine learning, can we also pursue simple and beautiful laws? There are still many such challenges, but we are still full of confidence in the future development of this field. Below, we will look ahead to some of the research hotspots in the next decade:
â–ŒExplainable Machine Learning
Various machine learning technologies represented by deep learning are in the ascendant and have achieved world-renowned success. Machines and humans are already on a par in many complex cognitive tasks. However, research in explaining why and how the model works is still at a very early stage.
Explain what: The gulf between correlation and causal logic.
Most machine learning techniques, especially those based on statistics, rely heavily on probabilistic prediction and analysis based on data correlation learning. On the contrary, rational human decision-making relies more on clear and credible causal relationships, which are inferred from true and clear factual reasons and logically correct rules. The transition from using data correlation to solve problems to using causal logic between data to explain and solve problems is one of the core tasks that interpretable machine learning needs to accomplish.
Why do you need to explain: Knowing is knowing, not knowing is not knowing, it is knowing.
Machine learning models analyze and make decisions based on historical data. But due to the lack of common sense, machines are likely to make low-level mistakes that are almost impossible for humans when faced with events that have never happened or are rare in history. Statistical accuracy does not effectively characterize the risk of a decision, and even in some cases the reasons behind seemingly correct probabilistic choices are contrary to the facts. In fields where controllability is the primary consideration, such as medical care, nuclear industry, and aerospace, understanding the factual basis behind data decisions is a prerequisite for applying machine learning. For these domains, interpretability means credible and reliable.
Explainable machine learning is still the only way to deeply integrate machine learning technology with our human society. The need for explainable machine learning is not only a desire for technological progress, but also includes various non-technical considerations, and even laws and regulations. The EU's GDPR (General Data Protection Regulation) regulations, which came into effect in 2018, clearly require that when a machine is used to make a decision against an individual, such as automatically rejecting an online credit application, the decision must meet certain requirements for interpretability.
In addition to the urgent need for interpretable machine learning in industry and society, the motivation to explain behavior is also the built-in ability and appeal of the human brain. Cognitive neuroscience pioneer Michael S. Gazzaniga made the following observations and conclusions in his study of Split-BrainPatients, which had a profound impact on modern cognitive science: "Our brains automatically seek (decision-making) Explanation and reason for the incident."
Who explains it to whom: Human-centered machine learning upgrades.
The question of who to explain it to is relatively clear. In short, explain to people. Depending on the audience, there are explanations that only machine learning experts can understand, as well as explanations that can be understood by the general public.
So who will explain it? Ideally, explained by a machine: The machine answers the question while giving the logical reasoning behind the answer. However, limited by how many machine learning techniques work, machine self-answering doesn’t always work. Many machine learning algorithms are "data in, model out". Most of the time, the causal relationship between the final conclusion drawn by the model and the input data becomes invisible, and the model has become a "magic" hacker. box.
At the stage where there is no effective solution for machine self-answering and self-explanation, solutions that support human review and retrospective answering process can provide a certain degree of interpretability. At this time, the interpretability of the action mechanism of each sub-module in the machine learning system becomes particularly important. For a large machine learning system, the overall interpretability is highly dependent on the interpretability of its individual components. The evolution from current machine learning to interpretable machine learning will be a systematic engineering involving all aspects, and it is necessary to comprehensively transform and upgrade the current machine learning from theory to algorithm to system implementation.
Degree of interpretability: from practicality to infinity.
Different application scenarios have different requirements for machine learning interpretability. In some cases, the professional explanation of "high and low" is enough, especially when the explanation is only used for technical security review; in other cases, when explainability is part of human-computer interaction, the popular "old woman can understand" An answer becomes necessary. Any technique only works to a certain extent and to a certain extent, and the same is true for machine learning interpretability. Explainable machine learning, from the need for practicality, is finally in endless continuous improvement.
â–ŒLightweight machine learning and edge computing
Edge computing refers to the processing and analysis of data at the edge nodes of the network. The edge node refers to the node with computing resources and network resources between the data generation source and the cloud computing center. For example, a mobile phone is an edge node between a person and a cloud computing center, and a gateway is a smart home and a cloud computing center. edge nodes between. In an ideal environment, edge computing refers to analyzing and processing data near the source of data generation, reducing the flow of data, thereby reducing network traffic and response time. With the rise of the Internet of Things and the widespread application of artificial intelligence in mobile scenarios, the combination of machine learning and edge computing is particularly important.
Why does edge computing play an important role in this embedded machine learning paradigm?
1. Data transmission bandwidth and task response delay: In mobile scenarios, machine learning tasks require a shorter response delay while requiring a large amount of data for training. In the case of autonomous driving, large delays can significantly increase the risk of accidents, requiring custom onboard computing equipment to perform model inference at the edge. Moreover, when a large number of devices are connected to the same network, the effective bandwidth will also be reduced, and the use of edge computing can effectively reduce the competition between devices on communication channels.
2. Security: Edge devices in edge computing can guarantee the security of the sensitive data collected. At the same time, edge computing can decentralize intelligent edge devices and reduce the risk of DDoS attacks affecting the entire network.
3. Customized learning tasks: Edge computing enables different edge devices to adopt customized learning tasks and models for different types of objects they face. For example, in the image recognition task in the security field, the image information observed by video devices in different areas may vary greatly, so just training one deep learning model may not achieve the goal, and hosting multiple models on the cloud at the same time will cost a lot of money. big. A more efficient solution is to train different models for each scenario in the cloud and send the trained models to the corresponding edge devices.
4. Multi-agent collaboration: Edge devices can also model multi-agent scenarios at the same time, helping to train reinforcement learning models for multi-agent collaboration.
So what are the challenges of embedding machine learning models, especially complex deep learning models, into the framework of edge computing?
1. Parameter-efficient neural networks: A striking feature of neural networks is the large parameter scale, and edge devices often cannot handle large-scale neural networks. This motivated the researchers to minimize the size of the neural network while maintaining model accuracy. The common approach now involves reducing the number of filters by squeezing and expanding the convolutional layers, thereby optimizing parameter efficiency.
2. Neural network pruning: There are some neurons in the training process of the neural network, and a large number of training on them cannot improve the final effect of the model. In this case, we can save model space by pruning such neurons.
3. Precision control: Most neural network parameters are 32-bit floating point numbers. Edge devices can be designed with 8-bit or fewer floating point numbers, and this reduction in precision can significantly reduce model size.
4. Model distillation: The process of model distillation is to transfer the ability of a trained complex neural network to a neural network with a simpler structure. Combined with the development of transfer learning, this approach can more effectively reduce model complexity without losing too much accuracy.
5. Optimized microprocessors: Another direction is to embed the learning and inference capabilities of neural networks on the microprocessors of edge devices. The potential shown by this AI chip has also received more and more attention.
â–ŒQuantum Machine Learning
Quantum machine learning (Quantum ML) is the intersection of quantum computing and machine learning.
Quantum computers process information using effects such as quantum coherence and quantum entanglement, which are fundamentally different from classical computers. Current quantum algorithms have outperformed the best classical algorithms on several problems, which we call quantum acceleration. For example, to search an unsorted database with N entries, the time required for a quantum algorithm is
When quantum computing encounters machine learning, it can be a mutually beneficial and complementary process: on the one hand, we can use the advantages of quantum computing to improve the performance of classical machine learning algorithms, such as efficiently implementing machine learning algorithms on classical computers on quantum computers. . On the other hand, we can also analyze and improve quantum computing systems using machine learning algorithms on classical computers.
Quantum Machine Learning Algorithms Based on Linear Algebra
Many quantum machine learning algorithms in this category are based on variants of quantum algorithms that solve systems of linear equations that solve N-ary linear equations under certain conditions such as the Hamiltonian condition, which is satisfied by sparse or low-rank matrices The complexity of the system of equations is . It should be pointed out that the complexity of any known classical algorithm for matrix inversion is at least . Quantum matrix-based inversion algorithms can accelerate many machine learning methods, such as least squares linear regression, least squares versions of support vector machines, Gaussian processes, etc. The training of these algorithms can be simplified to solving linear equations. The key bottleneck of this class of quantum machine learning algorithms is the data input, how to initialize the quantum system with the features of the entire dataset. Although efficient data entry algorithms exist for some specific cases, for most cases it is unknown how the data is entered into the quantum system.
. Quantum matrix-based inversion algorithms can accelerate many machine learning methods, such as least squares linear regression, least squares versions of support vector machines, Gaussian processes, etc. The training of these algorithms can be simplified to solving linear equations. The key bottleneck of this class of quantum machine learning algorithms is the data input, how to initialize the quantum system with the features of the entire dataset. Although efficient data entry algorithms exist for some specific cases, for most cases it is unknown how the data is entered into the quantum system.
Quantum Reinforcement Learning
In quantum reinforcement learning, a quantum agent interacts with a classical environment and receives rewards from the environment to adjust and improve its behavioral policies. In some cases, quantum acceleration is achieved due to the quantum processing capabilities of the agent or due to the possibility of quantum superposition probing the environment. Such algorithms have been proposed in superconducting circuits and trapped ion systems.
Quantum Deep Learning
Specialized quantum information processors such as quantum annealers and programmable photonic circuits are well suited for building deep quantum learning networks. The simplest quantizable deep neural network is the Boltzmann machine. A classical Boltzmann machine consists of bits with tunable interactions, and the Boltzmann machine is trained by adjusting the interaction of these bits so that the distribution of its expression conforms to the statistics of the data. To quantize a Boltzmann machine, a neural network can simply be represented as a set of interacting quantum spins, which corresponds to a tunable Ising model. Then by initializing the input neurons in the Boltzmann machine to a fixed state, and allowing the system to thermalize, we can read out the output qubits to get the result.
Quantum annealers are specialized quantum information processors that are easier to build and scale than general-purpose quantum computers, and are currently preliminarily commercialized, such as the D-wave quantum annealer.
â–ŒSimple and beautiful laws
Nature is full of complex phenomena and systems. Looking at the nature behind the complex phenomena in the real world, we can get an unexpected conclusion: seemingly complex natural phenomena are described by simple and beautiful mathematical laws, such as partial differential equations. The founder of Mathematica, well-known computer scientist, physicist Stephen Wolfram has made similar observations and conclusions: "It turns out that almost all traditional mathematical models in physics and other scientific fields are ultimately based on partial differential equations." Since natural The simple and beautiful mathematical laws behind phenomena are so common (especially partial differential equations), so can a method be devised to automatically learn and discover the mathematical laws behind phenomena? This problem is obviously difficult, but not completely impossible.
For any equation, some kind of equality must exist. So further, is there an inherent, universal conservation or invariant in the real physical world? On this issue, German mathematician Emmy Noether put forward the insightful Noether's theorem in 1915. The theorem states that for every continuous symmetric transformation there is a conserved quantity (invariant) corresponding to it. In other words, there is a one-to-one correspondence between continuous symmetry and conservation laws. This provides profound theoretical guidance for discovering the conservation relationship behind natural phenomena, especially for finding the conservation laws of physics. In fact, most of the formulas of physical laws are derived based on the conservation of certain quantities. For example, the Schrodinger equation that describes the quantum system is derived from the conservation of energy.
Based on this insight, scientists have carried out a lot of attempts and achieved fruitful results. For example, in their 2009 Science paper, Schmidt and Lipson proposed an automatic law discovery method based on the principle of invariants and evolutionary algorithms. The paper explores the topic that, given experimental data, we can generate a large number of equations or equations based on some invariance. So, what kind of correlations are important and meaningful? Although this question is difficult to answer quantitatively, Schmidt and Lipson make their point in their paper: A valid formulation based on some invariant must correctly predict the dynamics among the various components of a system. Specifically, a meaningful conservation formula must correctly characterize the relationship between the derivatives of a set of variables with respect to time.
Compared with deep learning, automatic law learning is more like Newton's method of observing and studying the world. After collecting a lot of data about the real world, Newton came up with a series of laws, equations and formulas that can be used to describe the laws of the physical world we live in concisely and clearly. Everything is number, and the discovery of the law of automation can greatly assist scientific research, and even realize the automation of scientific research in a certain field.
Impromptu learning
The impromptu learning we discuss here has similar goals to the predictive learning that Yann LeCun has been advocating, but the assumptions about the world and the methodology adopted are very different. Predictive learning is a concept that grew out of unsupervised learning and focuses on the ability to predict the probability of future events. Methodologically, predictive learning utilizes all currently available information to predict the future based on the past and present, or analyze the past based on the present. Predictive learning to some extent coincides with modern cognitive science's understanding of brain capabilities.
The two main elements of predictive learning are: modeling the world and predicting what is currently unknown. The question is, is the world we live in predictable? The answer to this question is unclear.
Unlike predictive learning, which assumes the world, improvised learning assumes that unusual events are the norm. Improvisational intelligence refers to the ability to improvise and solve problems when faced with unexpected events. Impromptu learning means that there are no definite, preset, static optimizable goals. Intuitively, ad hoc learning systems require continuous, self-driven improvement, rather than evolution driven by optimized gradients generated by preset goals. In other words, impromptu learning acquires knowledge and problem-solving skills through autonomous observation and interaction.
An improvised learning system learns from positive and negative feedback from observing and interacting with the environment. This process is superficially similar to reinforcement learning, but the essential difference is that ad hoc learning does not determine a preset optimization goal, while reinforcement learning usually requires a preset goal. Since ad hoc learning is not evolution driven by learned gradients based on a fixed optimization objective. So, what drives this learning process? When will this learning process stop? Here, we use the "conditional entropy" model as an example to discuss this type of learning system.
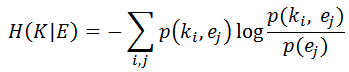
Here K is the knowledge currently possessed by the learning system and E is the information in the environment. This formula captures the "uncertainty" of the environment relative to the current learning system. With the transfer of "negative entropy", the learning system acquires more and more knowledge about the environment, and this "uncertainty" gradually decreases until it disappears. When this "uncertainty" completely disappears, the flow of "negative entropy" stops and the learning process ends. At this time, the learning system acquires a comprehensive understanding of the environment through impromptu learning without pre-set goals.
social machine learning
The purpose of machine learning is to simulate the human learning process. Although machine learning has achieved great success, it has so far ignored an important factor, that is, the social attributes of people. Each of us is a part of society, and it is difficult to live, learn, and progress independently from society from birth. Since human intelligence is inseparable from society, can we make machines also have some meaningful social attributes and simulate the evolution of key elements in human society, so as to achieve more effective, intelligent, and reliable than the current machine learning methods? What about "social machine learning" explained?
Society is composed of billions of human individuals, and social machine learning should also be a system composed of machine learning agents. In addition to acquiring data according to the current machine learning method, each machine learning algorithm also participates in social activities. They will cooperate with other machine learning agents to actively obtain information, divide labor, cooperate, and obtain social rewards according to social mechanisms. At the same time, they learn from experience, learn knowledge, and learn from each other to adjust their behavior.
In fact, sporadic shadows of "social intelligence" are beginning to appear in current machine learning methods. For example, "knowledge distillation" can describe the simplest behavioral influence between machine learning agents, and it may also be a preliminary way to acquire knowledge; methods such as model averaging, model integration, and voting in distributed machine learning algorithms are the simplest social Decision-Making Mechanisms; Reinforcement Learning provides a framework for agents to adjust their behavior based on reward feedback.
Since social attributes are the essential attributes of human beings, social machine learning will also be an important direction for us to use machine learning from acquiring artificial intelligence to acquiring social intelligence!
â–ŒConclusion
As mentioned above, machine learning has developed rapidly in recent years, and we are full of confidence in it. The future directions mentioned in this article are only based on the author's understanding of the field of machine learning, and there must be many important directions that are not covered. In fact, predicting the future is a very difficult thing, especially for the fast-growing field of machine learning. Alan Kay once said: "The best way to predict the future is to create it". therefore. We call on all machine learning practitioners, whether academics or engineers, professors or students, to work together and move forward hand in hand, use our practical actions to advance these important research topics, and use our hands to create the future, which will Much more real and important than predicting the future!
Car Screen Protector,Car Center Console Screen Protector,Car Touchscreen Screen Protector
Shenzhen Jianjiantong Technology Co., Ltd. , https://www.hydrogelprotectivefilm.com