![<?echo $_SERVER['SERVER_NAME'];?>](/template/twentyseventeen/skin/images/header.jpg)
Author: Qiu Lu Lu
The trend of artificial intelligence has spread all the way from technology to hardware, making "chips" a prevailing theme in the industry this year. People pay attention to the constantly refreshing benchmarks of CPUs and GPUs in the field of general-purpose chips, and have shown unprecedented enthusiasm for solutions that continue to appear in different scenarios in the field of application-specific chips (ASIC).
As we all know, there is a more flexible and mysterious area between dedicated chips and general-purpose chips: FPGAs. Whether it is Intel's sky-high price acquisition or Microsoft and IBM's ambitious plans, people are even more curious about it. The name of the "universal chip" and its diversified scope of responsibility: it can be a small component in a smart phone, or it can be a development board worth thousands of dollars, which makes people more confused about its true appearance.
What is the relationship between FPGA and deep learning? What kind of operations is it suitable for accelerating? Which scenarios are suitable for application? In June, Machine Heart interviewed Chen Deming, a professor from the Department of Electrical and Computer Engineering (UIUC ECE) of the University of Illinois at Urbana-Champaign, and the founder of Inspirit IoT, a startup company for deep learning algorithm hardware acceleration solutions, and talked with him about the "universal chip" FPGA in Usage in the field of deep learning. Professor Chen recently announced that he will concurrently serve as the chief scientist of Touch Jing Wu, a startup company in the field of computer vision in China.
The following is an interview transcript.
The Heart of the Machine: From the perspective of algorithms, what kind of operations are FPGAs suitable for accelerating?
The advantage of FPGA lies in customizable parallelism. It can customize logic units for specific algorithms. For example, the algorithm needs to complete a square root operation, and a long sequence of instructions is needed to implement it on a general-purpose chip, but a unit can be designed for this specific operation on the FPGA.
An example of the “limit†of customization is that if all the parameters and feature maps in the neural network can be binarized, then it is even possible to use exclusive OR gates instead of multipliers ( XOR gate) complete the calculation, there will be an extremely powerful performance. Even if not all binarization, because all binarization will significantly reduce the accuracy, as long as the reasonable use of various low-bit width operations, FPGA can still shine. For example, in our recent ELB-NN project with IBM, we can make the neural network's computing power on the FPGA reach 10.3 TOPS when the power consumption is less than 5 watts, while still maintaining a very high accuracy.
Another example is Microsoft’s Brainwave FPGA project, which can achieve 40 TOPS on high-capacity FPGAs by using special 8-bit floating point operations.
It is worth mentioning that every step of the operation of neural networks such as LSTM is very similar. This kind of algorithm whose overall operation process is sequential is also very suitable for acceleration with FPGA. FPGA is very good at processing streaming data, and can design a pipeline mechanism so that the intermediate data does not need to be stored in the memory during the operation, but directly sent to the next step for operation.
Heart of the Machine: Compared with other chips, what advantages does FPGA have when implementing deep learning models?
FPGA has more pins than ordinary chips, and its logic unit can be completely reorganized according to the algorithm requirements to produce a customized data path (datapath), so it is very suitable for processing large batches of streaming data. It does not need to repeatedly retrieve data from off-chip storage like a GPU. In an ideal state, as long as the data flows in and out again, the algorithm is complete. Therefore, FPGAs are very suitable for tasks with low latency requirements.
In addition, the fast speed and low power of FPGA also give it a great advantage over CPU and GPU in terms of energy consumption.
For example, we have implemented a Long-term Recurrent Convolutional Network (Long-term Recurrent ConvoluTIonal Network) on the FPGA. Its latency is 3.1 times faster than the GPU, and the power of the FPGA is 5.6 times smaller than that of the GPU. Finally, the overall energy consumption is reduced by about 17 times. .
Heart of the Machine: From an industry perspective, what machine learning and deep learning tasks can FPGA be used to accelerate?
In the terminal, some autopilot companies use FPGA in their on-board systems to complete some real-time detection and recognition tasks. For example, on behalf of UIUC, I once communicated with Xiaopeng Motors vice president and machine learning expert Gu Junli. She mentioned that FPGA can become a reliable second system by virtue of its advantages in signal processing and low energy consumption. When the system makes a mistake, it intervenes as a safe mode. There are even more IoT applications. Whether it is security or smart home, FPGAs will have the opportunity to enter the market.
In the cloud, there is also a huge space for integrating FPGAs. Before, Microsoft's Project Catapult built a large-scale FPGA cloud server. Catapult is now running search and data storage operations. At the same time, they are also actively thinking about how to deploy machine learning operations on it, including whether they can use FPGA as the back-end support for their Azure cloud. Amazon AWS' FPGA cloud computing is already very large and has been vigorously promoted. Recently, the domestic start-up company Shenjian has also begun to combine Huawei's cloud FPGA to accelerate deep learning algorithms, especially in LSTM-based speech recognition.
Heart of the Machine: Can you tell me the difference between using high-level synthesis (HLS) to automatically generate register-level (RTL) implementation and manual implementation with hardware description language (HDL)?
For deep learning related algorithms, HLS has advantages.
When you read a deep learning model described in high-level language, you will find that the model is regular. For example, the convolution operation is a six-level nested loop in C language. At this point, I can develop an IP core for this cycle, determine how to pipelining, how to allocate storage, etc., and then use the IP core on the FPGA, so that all convolutional layers in the neural network share the IP Just nuclear.
At this time, the design optimization points are the size of the IP core, whether multiple IP cores are required for parallel operation, etc. This is a very suitable scenario for HLS, because HLS can automatically and quickly explore different solutions. If RTL is adopted, many engineers are required to form multiple teams, and each team focuses on exploring one direction based on the engineer’s past design experience. This is a very costly process.
RTL is a hardware description language that describes the spatial relationship and logical timing of the hardware. This is a difficult language to learn. There are not many practitioners who can master it proficiently. Development and testing are slow. To exaggerate, if the HLS development cycle is calculated in days and weeks, then RTL is usually in months and years.
From the perspective of the final result, the RTL completely manual modulation solution is likely to be better than the HLS automatically generated solution. We have made a comparison. In the context of deep learning, the gap between HLS and RTL methods is about 10%.
Therefore, the question is whether you are willing to spend 3-5 times the time to get an extra 10% effect.
Heart of the Machine: What did the researchers do to simplify the FPGA development process?
Our team has developed a research tool that is a C language template library that can automatically generate C language expressions based on Caffe and TensorFlow codes. Then the researcher can give the C language code to the HLS tool to generate RTL code.
C language is a language commonly mastered by software engineers. Such tools allow software engineers to also have FPGA development capabilities, and allow developers to focus more on algorithms without too much consideration of the underlying hardware.
Moreover, the intermediate results in this process can be derived, and professionals can also optimize on the basis of automatic generation. All in all, the efficiency of the entire development has been greatly improved.
This is just an example. There are many other researchers working on various tools and platforms to improve the efficiency and quality of deep learning design. Both industrial and academic. For academics, such as teacher Cong Jingsheng from UCLA, and teacher Zhang Zhiru from Cornell. The industry leaders are some tools designed by Xilinx and Intel.
Heart of the Machine: What work has each major company done in FPGA application? What are the ideas for market expansion?
IBM and Xilinx are collaborating on the Power series and are committed to adding more storage to the FPGA. On the latest prototype, the storage is added to 64G, which is huge compared to the largest 8 or 16G currently available on the market. The data bandwidth is expanded for processing related to big data.
Intel acquired Altera and is committed to helping Altera develop tools such as compilation. This is an idea of ​​FPGA commercialization, just like GPU, maybe there will be an FPGA co-processor next to the CPU to complete the work in PCs in the future. Or at the chip level, there is an FPGA on the CPU chip. All in all, once the tools are ready, there will be many opportunities for integration. Intel has many ideas in smart cities and smart manufacturing, and hopes to realize them through FPGA.
Then there is Microsoft. Its main idea is cloud computing. In addition to Bing, it also hopes to use FPGAs in the Azure cloud for machine learning tasks.
Heart of the Machine: Can you tell us which products Inspirit IoT has achieved the acceleration of deep learning algorithms on FPGA?
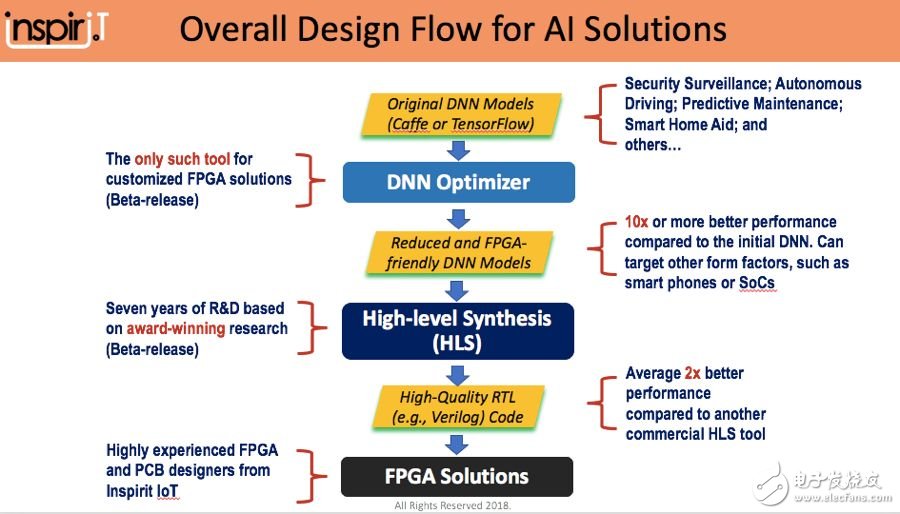
Our company mainly has three products, which are DNN optimizer, high-level integrated acceleration compiler (HLS compiler), and overall FPGA solutions according to the level.
The goal of the DNN optimizer is to customize an FPGA-friendly model and remove the redundant part of the trained model for reasoning. For example, the floating-point numbers used in training can be replaced with fixed-point numbers. There are many units in each layer during training, but pruning can be performed during inference, and so on. The DNN optimizer is based on various high-level framework models, and automatically optimizes according to the characteristics of the hardware and the characteristics of the scene.
The high-level comprehensive compiler allows developers to bypass writing the Verilog hardware description language and directly compile C, C++, CUDA and other codes into FPGA, which aims to reduce the threshold of hardware development and improve the productivity of software engineers. Our feature is that this compiler can naturally combine various IP cores in deep learning algorithms, which can best optimize the high-speed and high-quality implementation of various deep learning algorithms on FPGA.
In addition, we also have development boards embedded in FPGA for sound-related application scenarios. Embedded FPGA and 4 microphones on it, can detect the sound source, improve sound quality, and can also be used in conjunction with other devices such as cameras. For example, after capturing specific sounds such as vehicle crashes and screams, you can switch the camera to record related videos, etc., in the hope of obtaining a "1+1>3" effect.
Some client may feel that 10th Laptop is little old, so prefer 11th Laptop or 12th laptop. However, you will the 10th cpu is even more powerful than 11th, but price is nearly no difference, especially you take in lot, like 1000pcs. As a professional manufacturing store, you can see Laptop i3 10th generation 8gb ram,i5 laptop 10th generation, intel i7 10th gen laptop, etc. It`s a really tough job selecting a right one on the too many choices. Here are some tips, hope help you do that easier. Firstly, ask yourself what jobs you mainly need this Gaming Laptop to do. Secondly, what special features you care more? Like fingerprint, backlight keyboard, webcam rj45, bigger battery, large screen, video graphics, etc. Finally, ask the budget you plan to buy gaming laptop. Thus you will get the idea which laptop is right one for you.
Except integrated laptop, also have graphic laptop with 2gb or 4gb video graphic, so you can feel freely to contact us anytime and share your basic requirements, like size, cpu, ram, rom, video graphics, quantity,etc. More detailed value information provided in 1-2 working days for you.
10th Laptop,Laptop I3 10th Generation 8gb Ram,I5 Laptop 10th Generation,10th Generation Laptop,Intel I7 10th Gen Laptop
Henan Shuyi Electronics Co., Ltd. , https://www.shuyitablet.com